Ricerca di donatori per il progetto CharityML

https://www.ledgerinsights.com/wp-content/uploads/2019/09/charity-810x476.jpg
Questo progetto fa parte del programma Udacity Data Scientist Nanodegree: Finding Donors for CharityML Project e l'obiettivo era applicare tecniche di apprendimento supervisionato sui dati raccolti per censimento negli Stati Uniti per aiutare un'organizzazione di beneficenza fittizia CharityML a identificare le persone che molto probabilmente donerebbero alla loro causa.
Iniziamo utilizzando il processo CRISP-DM (Cross Industry Process for Data Mining):
- Comprensione del business
- Comprensione dei dati
- Preparazione dei dati
- Modellazione dei dati
- Valutazione dei risultati
- Deploy
Comprensione del business
CharityML è un'organizzazione di beneficenza fittizia che vuole espandere la propria base di potenziali donatori inviando lettere ai residenti della regione in cui si trova, ma solo a coloro che molto probabilmente donerebbero. Dopo che quasi 32.000 lettere sono state inviate a persone della comunità, CharityML ha stabilito che ogni donazione ricevuta proveniva da qualcuno che guadagnava più di $ 50.000 all'anno. Quindi il nostro obiettivo è costruire un algoritmo per identificare al meglio i potenziali donatori e ridurre i costi generali di invio della posta.
Comprensione dei dati
Il set di dati è composto da 45222 record e proviene dall'UCI Machine Learning Repository. Il set di dati è stato donato da Ron Kohavi e Barry Becker, dopo essere stato pubblicato nell'articolo "Scaling Up the Accuracy of Naive-Bayes Classifiers: A Decision-Tree Hybrid"
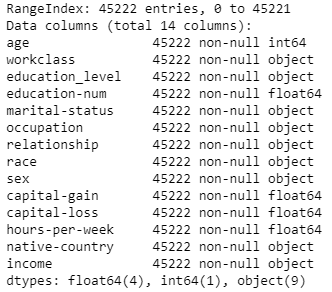
Attributi del set di dati

I primi 5 record come esempio
Riassumendo le variabili sono:
- età: continua
- classe-di-lavoro: privato, lavoratore autonomo non dipendente, lavoratore autonomo dipendente, governo federale, governo locale, governo statale, senza retribuzione, mai lavorato
- educazione_livello: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool
- educazione-num: continua
- stato-civile: Sposato-coniuge-civ, Divorziato, Mai-sposato, Separato, Vedovo, Coniugato-coniuge-assente, Coniugato-AF-coniuge
- occupazione: Supporto tecnico, Riparazioni artigianali, Altri servizi, Vendite, Dirigente-manageriale, Professionista-specialista, Manipolatori-pulitori, Macchina-su-ispezione, Amministrativo-impiegato, Agricoltura-pesca, Trasporto-trasloco, Casa privata- serv, Protective-serv, Forze armate
- relazione: moglie, figlio proprio, marito, non in famiglia, altro parente, celibe
- razza: nero, bianco, asiatico-Pac-isolano, amer-indiano-eschimese, altro
- sesso: femmina, maschio
- capital-gain: continua
- capital-loss: continua
- ore-settimanali: continua
- paese di origine: Stati Uniti, Cambogia, Inghilterra, Portorico, Canada, Germania, Periferia degli Stati Uniti (Guam-USVI-etc), India, Giappone, Grecia, Sud, Cina, Cuba, Iran, Honduras, Filippine, Italia , Polonia, Giamaica, Vietnam, Messico, Portogallo, Irlanda, Francia, Repubblica Dominicana, Laos, Ecuador, Taiwan, Haiti, Colombia, Ungheria, Guatemala, Nicaragua, Scozia, Tailandia, Jugoslavia, El-Salvador, Trinadad&Tobago, Perù, Hong , Olanda-Paesi Bassi
- reddito: >50K, <=50K
Come possiamo vedere dall'analisi preliminare, il nostro set di dati è sbilanciato perché, ovviamente, la maggior parte degli individui non guadagna più di $ 50.000, quindi, come spiegheremo meglio nella sezione Naive Predictor, questo può avere un impatto sull'accuratezza del modello che svilupperemo
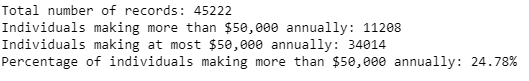
Analisi preliminare sui dati
Trasformazione delle variabili continue asimmetriche
Gli algoritmi possono essere sensibili a tali distribuzioni di valori e possono sottoperformare se l'intervallo non è adeguatamente normalizzato, quindi è pratica comune applicare una trasformazione logaritmica sui dati in modo che i valori molto grandi e molto piccoli non influenzino negativamente il prestazioni di un algoritmo di apprendimento. Con il set di dati del censimento due variabili corrispondono a questa descrizione: capital-gain e capital-loss
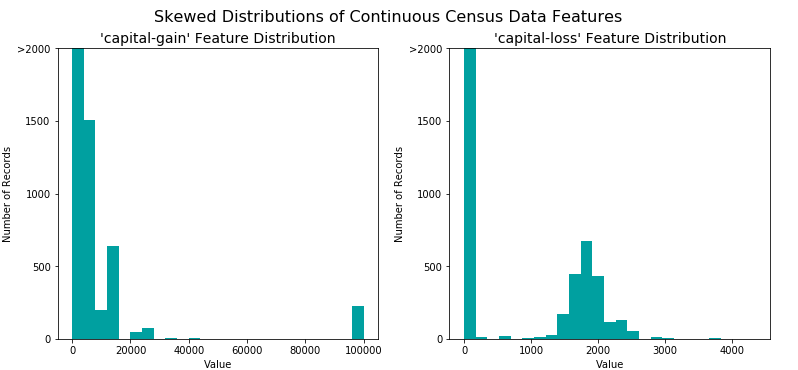
Distributioni asimmetriche capital-gain and capital-loss
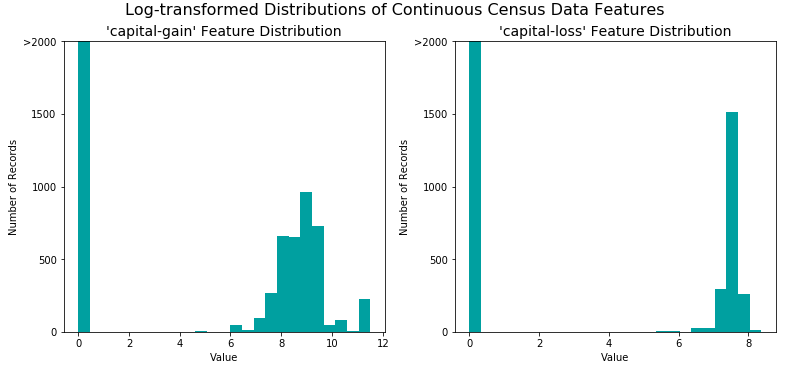
Trasformazione logaritmica delle variabili capital-gain e capital-loss
Normalizzazione delle variabili numeriche
L'applicazione di un ridimensionamento ai dati non modifica la forma di ciascuna distribuzione delle variabili. Utilizzeremo sklearn.preprocessing.MinMaxScaler per età, educazione-num, ore-settimanali, capital-gain e capital-loss.
Preparazione i dati
La conversione delle variabili categoriche avviene utilizzando lo schema di codifica one-hot

Esempio di codifica One-Hot
Come sempre, divideremo ora i dati (sia le variabili che le relative etichette) in set di training e test. L'80% dei dati verrà utilizzato per il training e il 20% per i test.
Modellazione dei dati
Lo scopo di generare un Naive Predictor è semplicemente quello di mostrare come sarebbe un modello base senza alcuna intelligenza. Come già detto, osservando la distribuzione dei dati, è chiaro che la maggior parte degli individui guadagna meno di 50.000 dollari all’anno. Pertanto un modello che prevede sempre "0" (ovvero l'individuo guadagna meno di 50.000) sarà generalmente corretto.

Risultati del Naive Predictor
Il fatto che il set di dati sia sbilanciato significa anche che la Accuracy non è molto utile perché anche se otteniamo un’elevata precisione, le previsioni effettive non sono necessariamente così buone. Di solito in questi casi si consiglia di utilizzare Precision e Recall
Confrontiamo i risultati di 3 modelli:
- Decision Trees
- Support Vector Machine
- AdaBoost

Metriche delle prestazioni

Matrici di confusione
Come già detto, ci stiamo concentrando sulla capacità del modello di prevedere con precisione coloro che guadagnano più di $ 50.000, il che è più importante della capacità del modello di richiamare tali individui. AdaBoostClassifier è quello che offre le migliori prestazioni sui dati dei test, sia in termini di Accuracy che di F-1 Score. Inoltre AdaBoostClassifier è anche abbastanza veloce da addestrare, come mostrato nell'istogramma Time-Training_set_size.
Ora ottimizzeremo il modello utilizzando sklearn.grid_search.GridSearchCV

Tuning del modello
Finalmente possiamo scoprire quali sono le variabili che forniscono il maggior potere predittivo. Concentrandoci sulla relazione tra solo alcune caratteristiche cruciali e l’etichetta target semplifichiamo la nostra comprensione del fenomeno. Possiamo farlo utilizzando feature_importance

Valutazione dei risultati
Il nostro obiettivo era prevedere se un individuo guadagna più di 50.000 all'anno perché le persone che soddisfano questo requisito sono più disposte a donare a un ente di beneficenza. Dopo aver ripulito i dati e averli modellati in un set di dati pronto per essere utilizzato per ML training, abbiamo testato le prestazioni di tre diversi modelli. Considerando F-1 Score il modello migliore è AdaBoostClassifier
Sponsorizzazione di vere organizzazioni di beneficenza
Voglio approfittare di questo articolo per parlare di alcune vere organizzazioni di beneficenza a cui tengo molto:
L’Associazione Italiana Sclerosi Multipla (AISM) è un’organizzazione no-profit che si occupa della sclerosi multipla

EMERGENCY è una ONG umanitaria che fornisce cure mediche gratuite alle vittime della guerra, della povertà e delle mine antiuomo

Save the Children migliora la qualità della vita dei bambini attraverso una migliore istruzione, assistenza sanitaria e opportunità economiche. Fornisce inoltre aiuti di emergenza in caso di catastrofi naturali, guerre e altri conflitti

https://www.savethechildren.it/
Outro
Spero che il post sia stato interessante e grazie
per aver dedicato del tuo tempo a leggerlo. Il codice per questo
progetto lo puoi trovare in questo repository github e sul mio Medium puoi trovare la stessa story in inglese. Fammi sapere se hai qualche domanda e se ti piacciono i contenuti che creo, sentiti libero di offrirmi un caffè.


Commenti
Posta un commento