Previsione dell'abbandono degli utenti tramite Spark

Questo progetto è il progetto finale del programma Udacity Data Scientist Nanodegree: Data Scientist Capstone. L'obiettivo è prevedere se un utente abbandonerà il servizio di musica digitale fittizio Sparkify
La previsione del tasso di abbandono è uno dei casi d'uso dei Big Data più popolari nel mondo degli affari. Come spiegato meglio in questo post, il suo obiettivo è determinare se un cliente annullerà o meno il suo abbonamento a un servizio
Iniziamo utilizzando il processo CRISP-DM (Cross Industry Process for Data Mining):
- Comprensione del business
- Comprensione dei dati
- Preparazione dei dati
- Modellazione dei dati
- Valutazione dei risultati
- Deploy
Comprensione del business
Sparkify è un servizio di musica digitale che può essere utilizzato gratuitamente ascoltando qualche pubblicità tra le canzoni o pagando una quota di abbonamento mensile per avere un'esperienza senza pubblicità. In qualsiasi momento gli utenti possono decidere di effettuare il downgrade da premium a free, l'upgrade da free a premium o la cancellazione dal servizio.
https://www.udacity.com/course/data-scientist-nanodegree--nd025
Comprensione dei dati
Il dataset fornito è sostanzialmente composto dal log di ogni azione dell'utente sulla piattaforma. Ogni azione è contrassegnata da un timestamp ts

Attributi del set di dati
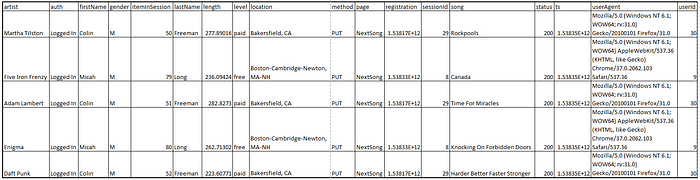
I primi 5 record come esempio
Dal piccolo set di dati abbiamo 286500 record di 225 utenti:
46% femmine e 54% maschi
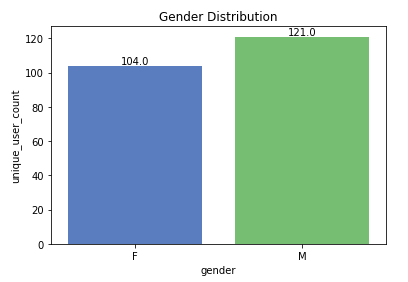
Distribuzione di genere nel piccolo set di dati
Il 54% delle interazioni proviene da utenti gratuiti e il 46% da utenti premium
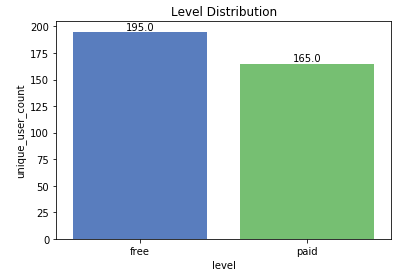
Distribuzione dei livelli nel piccolo set di dati
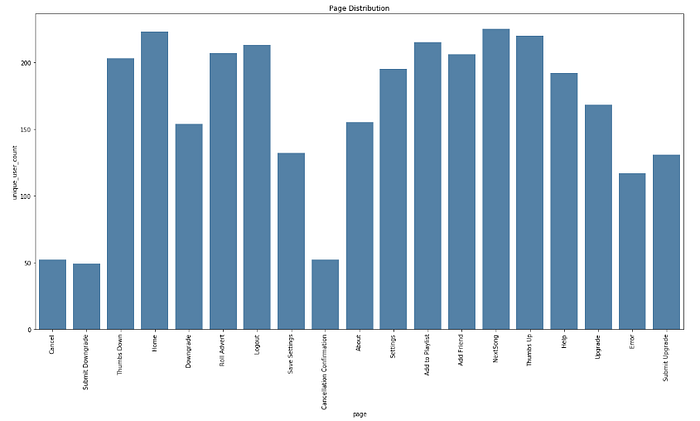
Distribuzione delle pagine nel piccolo set di dati
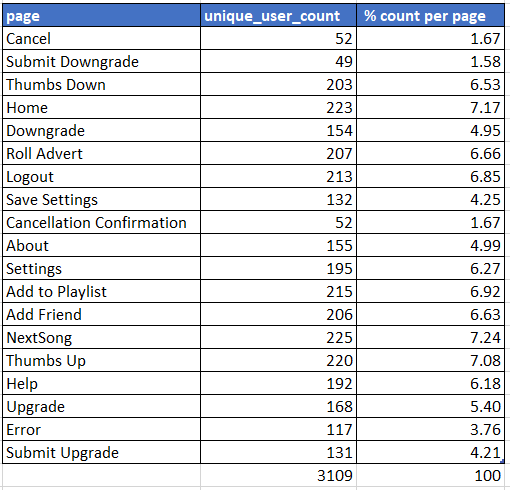
% di distribuzione delle pagine nel piccolo set di dati
I record hanno un arco temporale da ottobre 2018 a dicembre 2018
Preparazione dei dati
Il primo passo è stato eliminare tutti i record con userId vuoto. La stringa vuota userId molto probabilmente si riferisce a utenti che non si sono ancora registrati o che sono disconnessi e stanno per accedere, quindi possiamo rimuovere questi record.
Quindi ho definito una nuova colonna Churn che verrà utilizzata come etichetta per il modello. Fondamentalmente, se un utente ha mai visitato la pagina di Cancellation Confirmation, lo contrassegneremo come abbandonato. Ovviamente questo evento può verificarsi sia per gli utenti paganti che per quelli gratuiti.
Otteniamo il 23% di utenti abbattuti e il 77% non abbattuti, quindi il set di dati è piuttosto squilibrato. Come spiegato in questo fantastico post, dobbiamo tenerlo a mente quando parleremo di metriche nella sezione Valutazione dei risultati
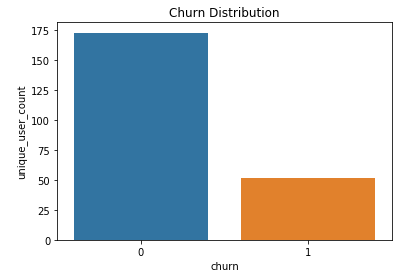
Churn distribution in the small dataset
Poi ho fatto un confronto di alcune caratteristiche considerando anche il valore Churn:
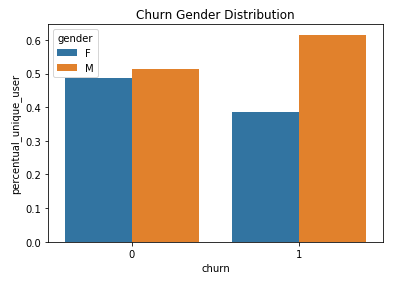
Churn Distribuzione di genere nel piccolo set di dati
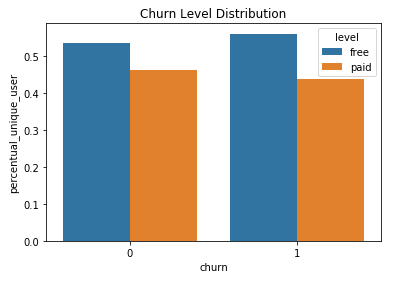
Distribuzione del Churn nel piccolo set di dati
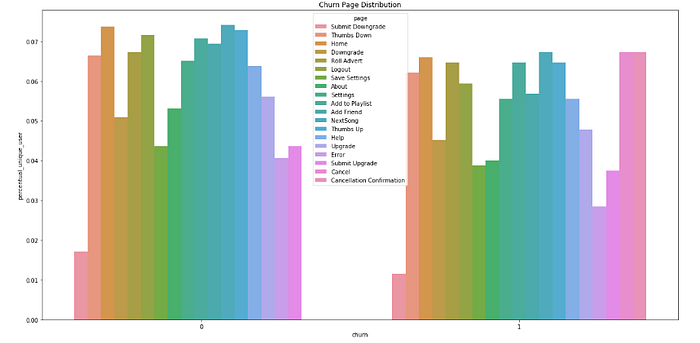
Churn Distribuzione delle pagine nel piccolo set di dati
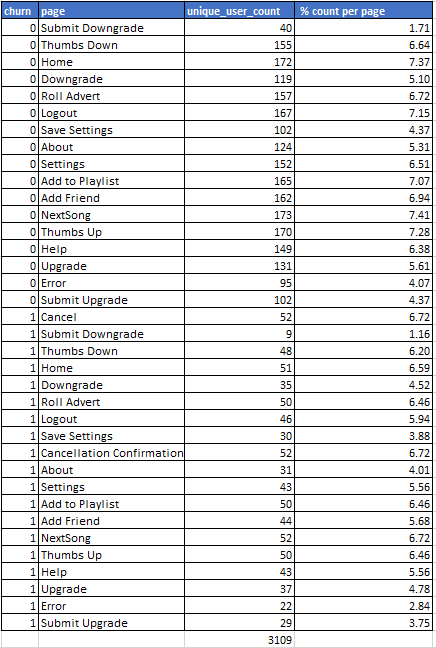
% churn distribuzione delle pagine nel piccolo set di dati
Modellazione dei dati
Tutte le caratteristiche categoriche che possono essere utili per il nostro compito sono state codificate a caldo e aggregate per userId:
- sesso
- livelli
- pagina
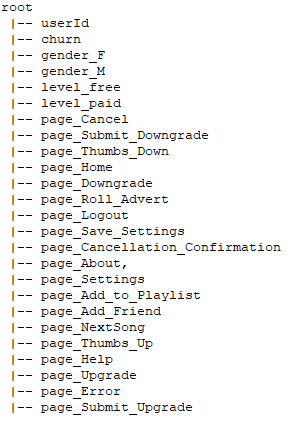
Attributi ingegnerizzati del set di dati
Quindi abbiamo aggiunto alcune interessanti funzionalità ingegneristiche ponendo queste domande:
- Da quanto tempo gli utenti sono iscritti al servizio? Il tasso di abbandono è correlato a questo?
- Attività dell'ultimo mese (per gli utenti abbattuti la cancellazione è l'ultimo mese prima della cancellazione) suddivisa in settimane
- Quanti artisti ha ascoltato un utente?
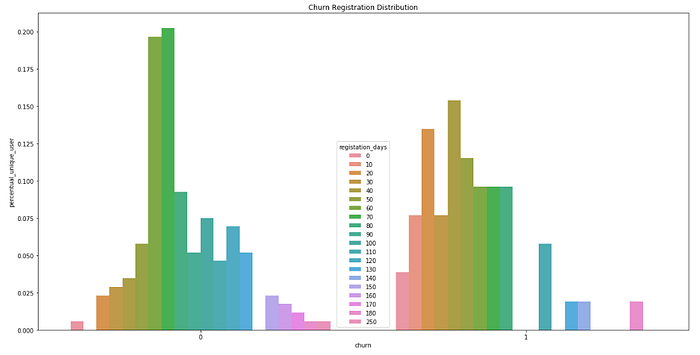
Distribuzione dei giorni di Churn Registration nel piccolo set di dati
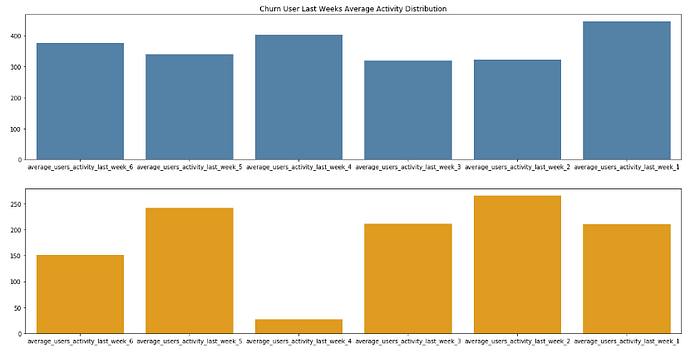
Distribuzione Churn media dell'attività della scorsa settimana nel piccolo set di dati
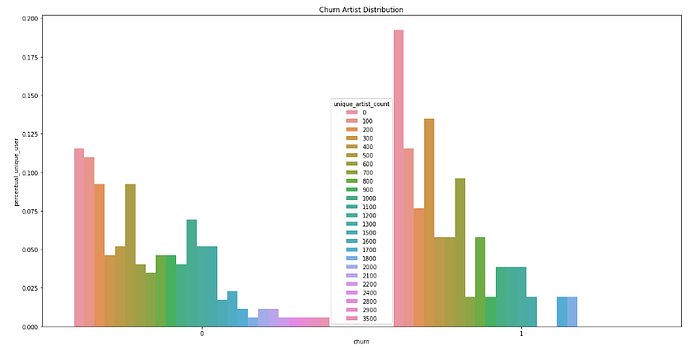
Distribuzione di Churn Artist nel piccolo set di dati
Il set di dati finale pronto per ML è simile al seguente:
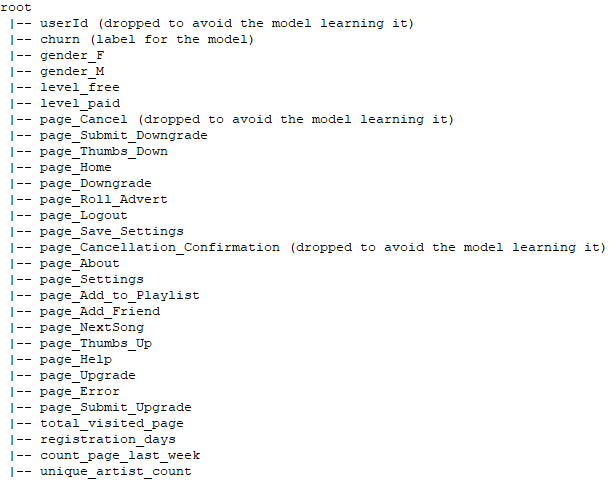
Attributi del set di dati ingegnerizzati in input al modello
È importante non considerare attributi come page_Cancellation_Confirmation o page_Cancel perché mappano esattamente la colonna dell'etichetta quindi l'accuratezza sarà sempre 100% perché in pratica stiamo imparando il valore che vogliamo prevedere
Valutazione dei risultati
Una matrice di confusione è una tabella che viene spesso utilizzata per descrivere le prestazioni di un modello di classificazione su un insieme di dati di test per i quali sono noti i valori reali.
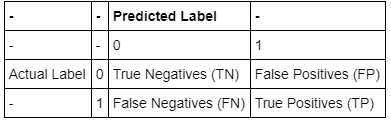
La Accuracy misura la frequenza con cui il classificatore effettua la previsione corretta. È il rapporto tra il numero di previsioni corrette e il numero totale di previsioni:
Accuracy = (True Positives + True Negative) / (True Positives + False Positives + True Negatives + False Negatives)
La Precision ci dice quale proporzione della previsione corretta era effettivamente corretta. È un rapporto tra i veri positivi e tutti i positivi:
Precision = True Positives / (True Positives + False Positives)
Recall (Sensitivity) ci dice quale proporzione di previsione che effettivamente era corretta è stata classificata da noi come corretta. È un rapporto tra i veri positivi e tutte le previsioni che erano effettivamente positive:
Recall = Veri Positivi / (Veri Positivi + Falsi Negativi)
F-beta score è una metrica che considera sia la precisione che il richiamo:
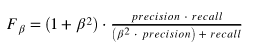
Lo scopo di generare un Naive Predictor è semplicemente quello di mostrare come sarebbe un modello base senza alcuna intelligenza. Come già detto, osservando la distribuzione dei dati, è chiaro che la maggior parte degli utenti non abbandoni. Pertanto, un modello che prevede sempre '0' (ovvero l'utente non visita la pagina Cancellation Confirmation) sarà generalmente corretto.
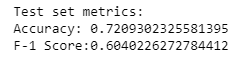
Il modello naive che etichetta tutti gli utenti con abbandono = 0 fa un buon lavoro sul set di test, con una Accuracy dell'81,2% e un F1 score di 0,7284
Il fatto che il set di dati sia sbilanciato significa anche che Accuracy non è molto utile perché anche se otteniamo un'accuratezza elevata, le previsioni effettive non sono necessariamente così buone. Di solito si consiglia di utilizzare Precision e Recall in questi casi
Confrontiamo i risultati di 3 modelli:
- Logistic Regression
- Gradient Boosted Trees
- Support Vector Machine
Il primo passaggio è stato rimuovere le colonne non necessarie per il training
colonne = df.columns[1:-1]
colonne 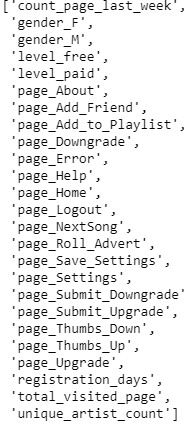
Features usate per ML training
quindi tutte le caratteristiche sono state vettorializzate (non è necessaria alcuna conversione perché tutte le caratteristiche erano già numeri)
assembler = VectorAssembler(inputCols = colonne, outputCol = ‘features’)
data = assembler.transform(df) lo StandardScaler() è stato utilizzato per ridimensionare i dati
scaler = StandardScaler(inputCol = 'features', outputCol = 'scaled_features', withStd = True)
scaler_model = scaler.fit(data)
data = scaler_model.transform(data)
Quindi ho suddiviso i dati in set di dati di addestramento, test e convalida
train, rest = data.randomSplit([0.6, 0.4], seed = 42)
validation, test = rest.randomSplit([0.5, 0.5], seed = 42)
Per tutti i modelli ho utilizzato F1 score come metrica
f1_evaluator = MulticlassClassificationEvaluator(metricName = ‘f1’) e ParamGridBuilder() e 3 volte CrossValidator() per determinare i migliori iperparametri per i modelli considerando tutti i parametri
param_grid = ParamGridBuilder().build() Logistic Regression
logistic_regression = LogisticRegression(maxIter = 10)
crossvalidator_logistic_regression = CrossValidator(estimator = logistic_regression, evaluator = f1_evaluator, estimatorParamMaps = param_grid, numFolds = 3)cv_logistic_regression_model = crossvalidator_logistic_regression.fit(train)
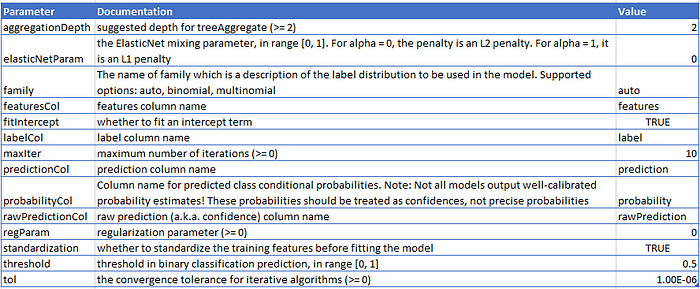
I parametri migliori
Gradient Boosted Trees
gradient_boosted_trees = GBTClassifier(maxIter = 10, seed = 42)
crossvalidator_gradient_boosted_trees = CrossValidator(estimator = gradient_boosted_trees, evaluator = f1_evaluator, estimatorParamMaps = param_grid, numFolds = 3)
cv_gradient_boosted_trees_model = crossvalidator_gradient_boosted_trees.fit(train) 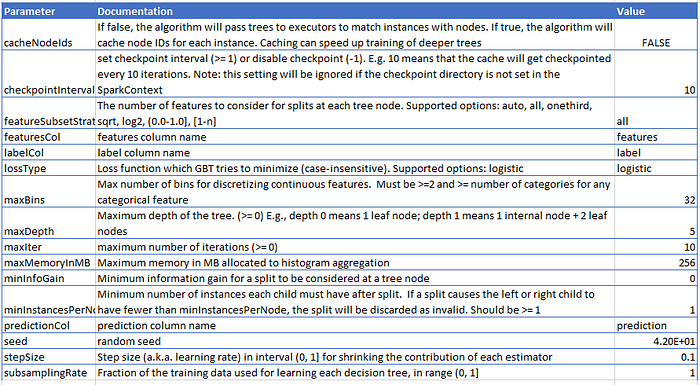
I parametri migliori
GBT permette anche di vedere l'importanza delle caratteristiche:
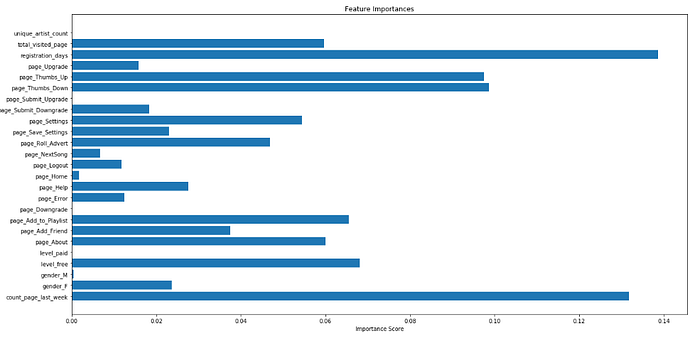
Caratteristiche importanti da GBT
Possiamo vedere che i registration_days e count_page_last_week hanno la massima importanza
Support Vector Machine
linear_svc = LinearSVC(maxIter = 10)
crossvalidator_linear_svc = CrossValidator(estimator = linear_svc, evaluator = f1_evaluator, estimatorParamMaps = param_grid, numFolds = 3)
cv_linear_svc_model = crossvalidator_linear_svc.fit(train)
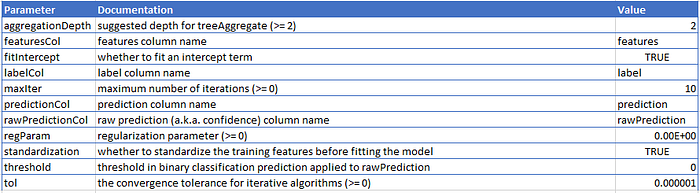
I parametri migliori
Complessivamente la Logistic Regression ha i migliori risultati con un F-1 Score di 0,8218 sul set di dati di test e 0,7546 sul set di dati di convalida
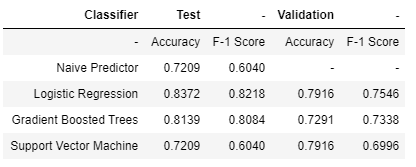
Risultati su set di dati di test e validazione
Raffinamento
La prima volta ho provato a regolare manualmente alcuni parametri per i modelli ma i risultati migliori sono stati ottenuti lasciando che ParamGridBuilder() e CrossValidator() cercassero tutti i parametri
Deploy
Come suggerito da Cloud Deployment Instructions for DSND Capstone Project, ho creato un cluster con AWS
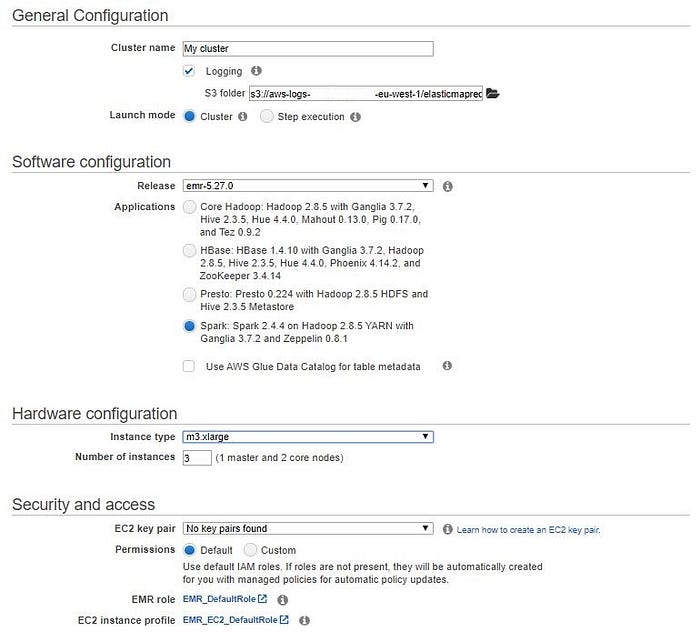
La mia configurazione del cluster
Come spiegato meglio qui, m3.xlarge è un'istanza EC2 per uso generico di seconda generazione dotata di Intel Xeon E5–2670 ad alta frequenza e 2 storage di istanze basato su SSD da 40 GB
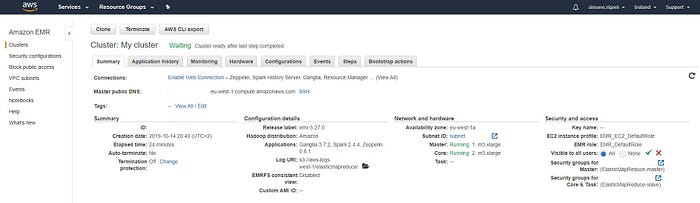
Riepilogo del mio cluster
Quindi ho creato un Notebook e ho copiato e incollato il codice necessario
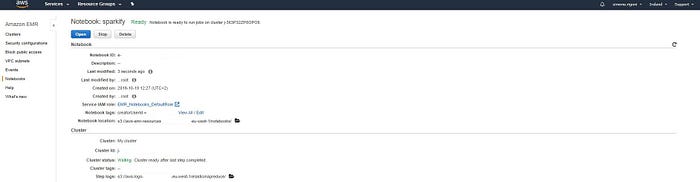
riepilogo notebook sparkify
Sul set di dati reale abbiamo 26259199 record di 22278 utenti:
47% femmine e 53% maschi
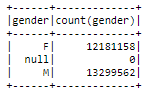
Distribuzione di genere nel set di dati completo
Il 21% delle interazioni proviene da utenti gratuiti e il 79% da utenti premium
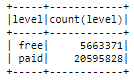
Distribuzione dei livelli nel set di dati completo
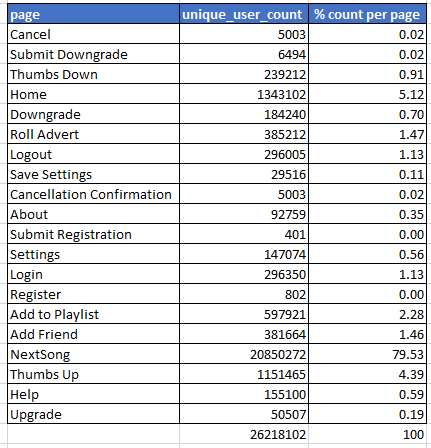
Distribuzione delle pagine nel set di dati completo
Il 22% degli utenti ha rinunciato e il 78% no
Il piccolo set di dati era una buona rappresentazione del set di dati reale, il che significa che sembra non essere distorto
Conclusioni
Il nostro obiettivo era prevedere se un utente si annullerà dal servizio per consentire all'azienda di fargli offerte o sconti per cercare di mantenere questi utenti. Dopo aver ripulito i dati e averli modellati in un set di dati pronto per essere utilizzato per l'addestramento ML, abbiamo testato le prestazioni di tre diversi modelli. Tutti i modelli risultanti hanno avuto successo nel prevedere se un utente lascerà il servizio o non molto meglio di un Naive Predictor che fornisce sempre la risposta "0" (gli utenti non rinunceranno). Considerando il F-1 Score, il modello migliore è la Logistic Regression. Nonostante i buoni risultati, il modello potrebbe essere migliorato creando funzionalità più ingegnerizzate per catturare alcuni modelli di comportamento che potrebbero essere correlati alla soddisfazione dell'utente del servizio: il motore di raccomandazione è buono? Significa che la canzone consigliata agli utenti incontra davvero i loro gusti. Dall'importanza delle funzionalità di GBT, le funzionalità grezze page_Thumbs_Up e page_Thumbs_Down sono piuttosto importanti, quindi una nuova funzionalità che cattura i gusti musicali degli utenti può davvero migliorare il modello
Outro
Spero che il post sia stato interessante e grazie
per aver dedicato del tuo tempo a leggerlo. Il codice per questo
progetto lo puoi trovare in questo repository GitHub e sul mio Medium puoi trovare la stessa story in inglese. Fammi sapere se hai qualche domanda e se ti piacciono i contenuti che creo, sentiti libero di offrirmi un caffè.


Commenti
Posta un commento