Vuoi trasferirti a Milano? Analisi del sentiment dei quartieri utilizzando i dati di Airbnb

Foto di Andrea Ferrario su Unsplash
Questo progetto fa parte del programma Udacity Data Scientist Nanodegree: scrivere un blog post riguardo alla data science e l'obiettivo era scegliere un set di dati, applicare il processo CRISP-DM (Cross Industry Process for Data Mining) e comunicare efficacemente i risultati dell'analisi.
Il processo CRISP-DM:
- Comprensione del business
- Comprensione dei dati
- Preparazione dei dati
- Modellazione dei dati
- Valutazione dei risultati
- Deploy
Guardando i set di dati suggeriti ero piuttosto bloccato a causa delle troppe opzioni. Poi, siccome io e alcuni amici stavamo pensando di trasferirci a Milano per essere più vicini ai nostri luoghi di lavoro, ho deciso di utilizzare i dati di Airbnb per fare una sentiment analysis dei suoi quartieri.
Comprensione del business
L'obiettivo del progetto era rispondere ad almeno tre domande relative alle applicazioni aziendali o del mondo reale su come i dati potrebbero essere utilizzati, quindi ho scelto:
- Quali sono i 5 quartieri con il punteggio più alto?
- Quali sono i 5 quartieri con il punteggio più basso?
- Quanto è diversa la panoramica del quartiere data dai padroni di casa da quella data dagli ospiti?
Comprensione, preparazione e modellazione dei dati
Il set di dati è composto da 20626 annunci di host e 469653 recensioni dei clienti. Sia gli annunci che le recensioni sono scritti in diverse lingue: italiano, inglese, francese, russo ecc.
Dopo aver capito quali dati potevano essere utili per il mio obiettivo ho dovuto mappare i quartieri dell'elenco con quelli reali: Milano è composta da 130 quartieri ma solo 74 erano coperti da almeno un elenco dopo la mappatura.
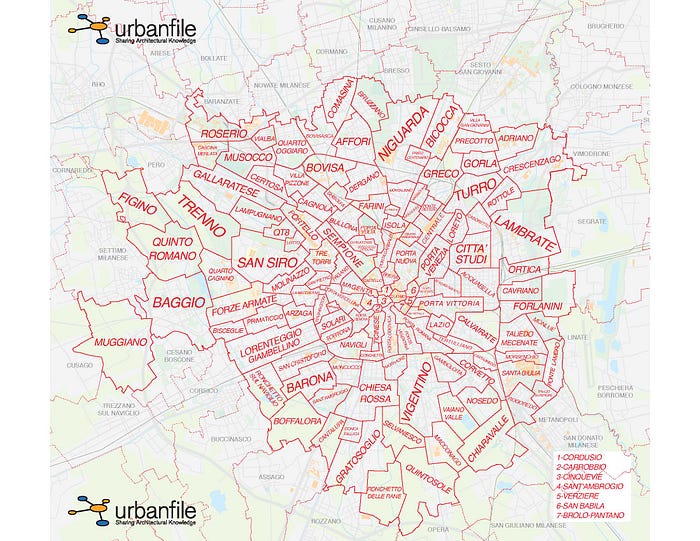
http://www.museomilano.it/mediateca/media-pg-5/
La mappatura è stata fatta anche manualmente utilizzando Google Maps dove non era possibile un approccio automatico.
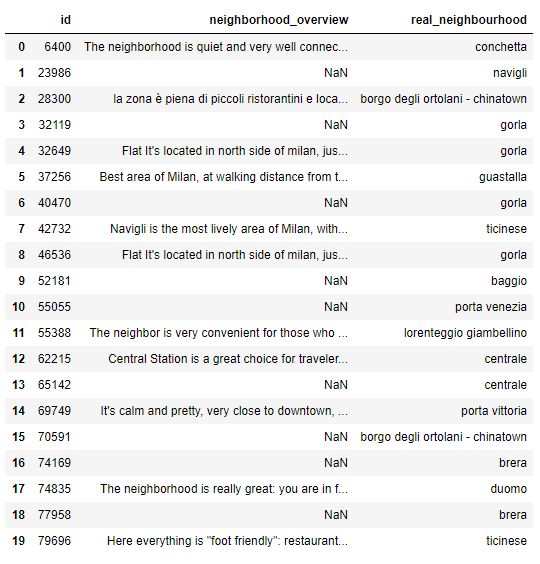
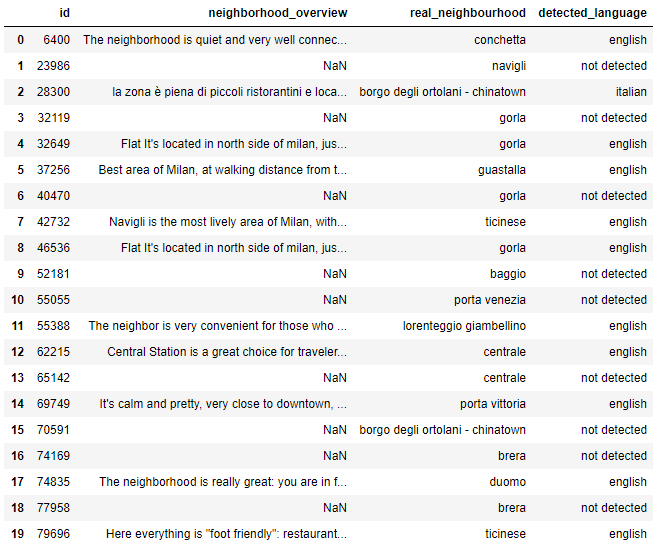
Primi 20 annunci contrassegnati con real_neighbourhood
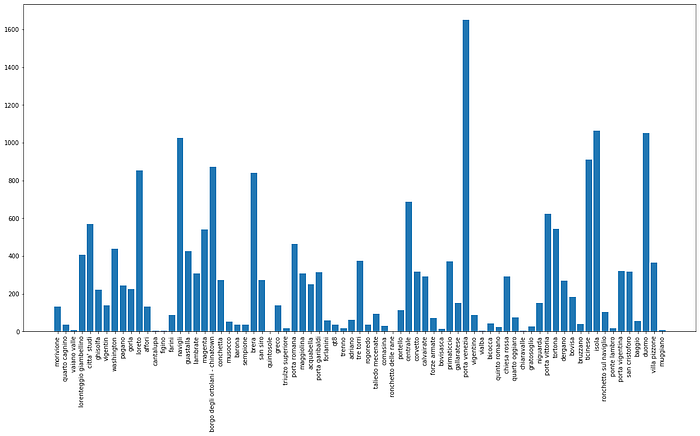
Numero di annunci relativo a un quartiere
Utilizzando il listing_id è possibile collegare ogni recensione al real_neighbourhood.
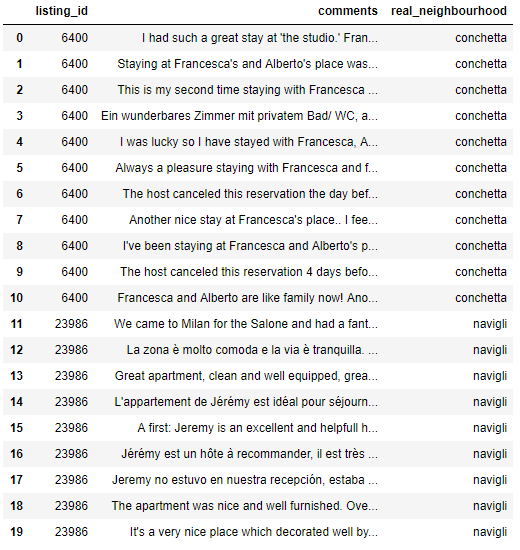
Le prime 20 recensioni contrassegnate con real_neighbourhood
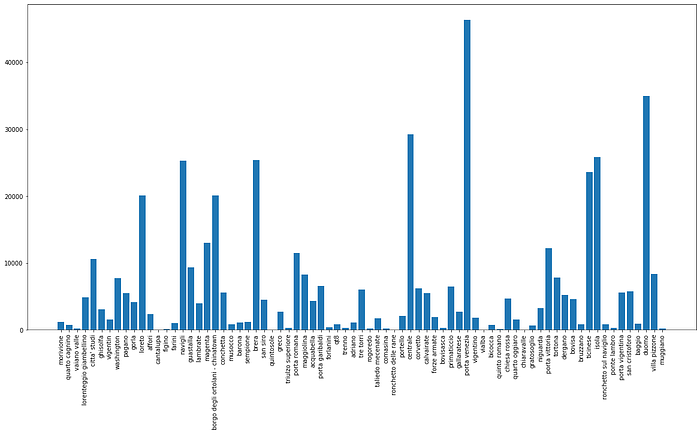
Numero di recensioni relative a un quartiere
Sia per le inserzioni che per le recensioni, ho rilevato la lingua utilizzata e contrassegnato ogni record.
Primi 20 elenchi contrassegnati con detect_language
Circa il 34% degli annunci ha una panoramica di quartiere con lingua non rilevabile, il 37% inglese e il 26% italiano.
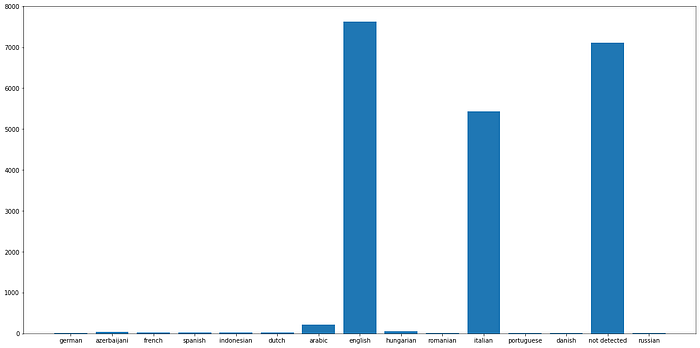
Listing neighbor_overview lingue rilevate
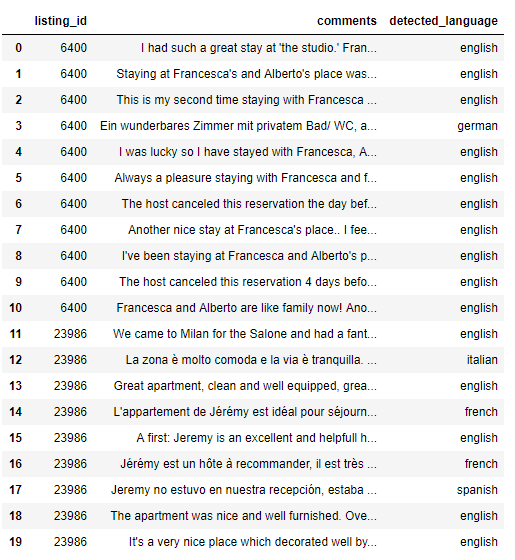
Le prime 20 recensioni contrassegnate con detect_language
Circa il 58% delle recensioni è in inglese e il 20% in italiano.
Quindi ho deciso di concentrarmi su elenchi e recensioni in inglese e utilizzare solo i record contrassegnati in questo modo. Nell'elencare utilizzando neighbor_overview possiamo ottenere direttamente il sentimento del quartiere ma per le recensioni per i commenti dobbiamo estrarre solo le frasi relative al quartiere.
Per ogni annuncio ora abbiamo un neighbor_sentiment
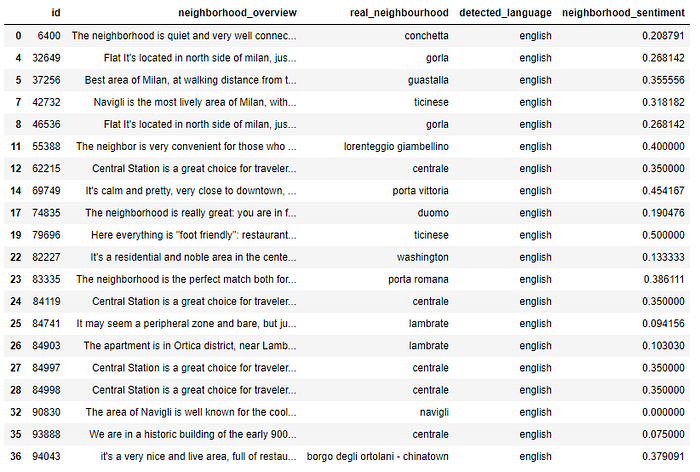
Primi 20 annunci contrassegnati con neighbor_sentiment
Lo stesso è stato fatto anche per la rassegna, estraendo le frasi relative al quartiere utilizzando un elenco di sinonimi: neighborhood, area, block, district, ghetto, parish, precinct, region, section, slum, street, suburb, territory, zone, location
Per esempio consideriamo il primo commento:
Staying at Francesca's and Alberto's place was a pleasure. Just as
described, well located for my purposes, an enjoyable walk to the
Tortona area. The room is very nice, cleaned daily and has private
bathroom.
Francesca is super friendly and very helpful; whilst still respecting privacy.
Overall a great experience!
Per il nostro scopo dobbiamo considerare solo:
Just as described, well located for my purposes, an enjoyable walk to the Tortona area
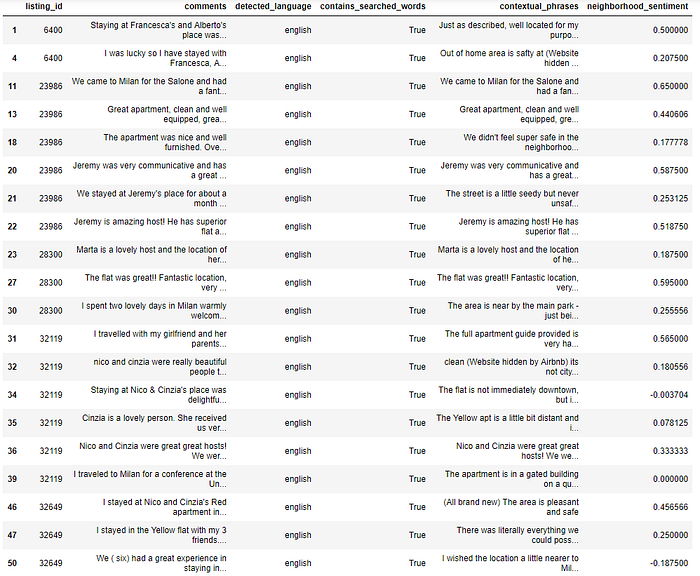
Le prime 20 recensioni contrassegnate con neighbor_sentiment
Ora raggruppando per quartiere otteniamo i sentimenti che stavamo cercando:
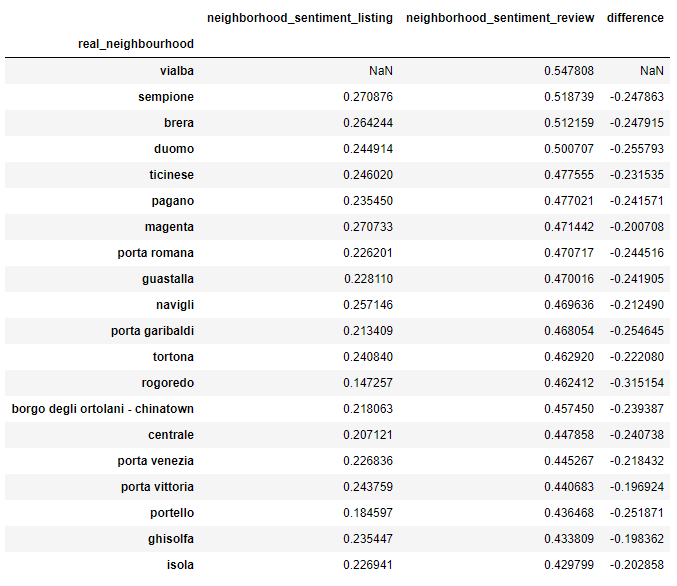
Confronto del sentimento dei primi 20 quartieri ordinato per neighbor_sentiment_review
Valutazione dei risultati
Le risposte alle nostre domande sono:
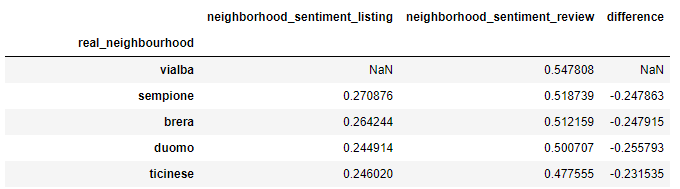
Primi 5 quartieri per punteggio
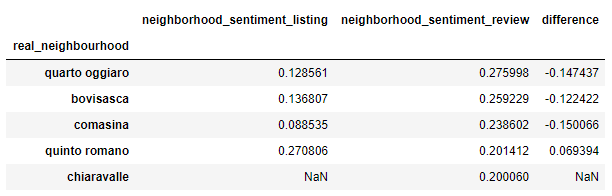
Ultimi 5 quartieri per punteggio
In media il sentiment del quartiere dato dalle frasi contestuali della recensione degli ospiti è molto più alto rispetto al neighborhood_overview dato dagli host. Una possibile spiegazione potrebbe essere l'ampia lunghezza del testo neighbor_overview che influenza negativamente il punteggio dell'analisi del sentiment. Mentre l'estrazione delle sole frasi utili permette di chiarire la stringa utilizzata per l'analisi, assegnando un punteggio complessivo più alto.
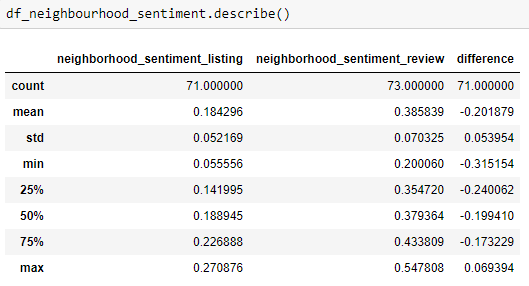
Reporting valori aggregati
Conclusioni
Riassumendo i passaggi:
- Mappare il quartiere del set di dati al quartiere reale
- Rilevare la lingua utilizzata in neighbor_overview per le inserzioni e i commenti per le recensioni
- Per le inserzioni: calcola l'analisi del sentiment di neighbor_overview
- Per le recensioni: isolare le frasi relative al quartiere e calcolare l'analisi del sentiment
- Confronta i risultati delle inserzioni e delle recensioni
Outro
Spero che il post sia stato interessante e grazie per aver dedicato del tuo tempo a leggerlo. Il codice per questo progetto lo puoi trovare in questo repository GitHub e sul mio Medium puoi trovare la stessa story in inglese. Fammi sapere se hai qualche domanda e se ti piacciono i contenuti che creo, sentiti libero di offrirmi un caffè.


Commenti
Posta un commento